This chapter describes the Back Propagation part of this
report. The result of the program described in this chapter can be found in the
next chapter. Here a quick description of the Back Propagation Algorithm can be
found as well as the choices regarding our network. The program is described as
well as the capabilities of it. And this chapter ends with a short description of the data
sets that has been chosen.
The term 'Back Propagate' means just what it says. To propagate some signal
backwards through the network, in this case it is the error and the reason we do
that is to train the network. Basically this chapter explains shortly what a
neural network is and how it is trained.
[ toc | previous | next | up ]
This is the fundamental building block of any neural networks. This neuron is
programmed to imitate the behaviour of the neurons in our brain. It can be
thought of as a black box with many inputs and one output, the axon. On each input
there is a weight which regulates how much that input is going to affect the
output. Inside the black box, all the inputs are added together and when the
sum exceeds a threshold value, the axon fires. This makes a pattern recognition
unit that can
be made to fire on a specific pattern, and it can be taught to
learn specific patterns by changing the weights.
[ toc | previous | next | up ]
A Feed Forward Network is made from Neurons and they are arranged in layers. Usually
models of three layers are used, one input layer (that does not contain any
neurons, but all the input signals), a hidden layer and an output layer which
both are made from Neurons. It is the last two layers that actually does
anything. All of the neurons inputs are connected to the previous layers
outputs. This structure is called a Feed Forward Network.
Forward Propagation is when you input the signal vector to the network through the
input layer and then check what outputs are generated on the output layer. When
the network is not trained, it can present almost anything on the outputs. It is the
possibility to train this network that makes it worth while.
[ toc | previous | next | up ]
This is a process to train a Feed Forward Network, it is called Back
Propagation because that is in essence what is done. The error from the outputs
are propagated backwards through the network so that the weights can be updated
to recognise the chosen pattern. This of course requires that there is a wanted
output from the input vector. This is also called Supervised learning.
[ toc | previous | next | up ]
The network that is used consists of only one hidden layer and the weights are
initialized to a random number between minus and plus
one, divided with the square root of the number of neurons in the same layer. As
shown in the following formula.
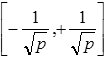
The momentum and learning rate was chosen to be a fixed value rather than an
adaptive one. They were both tested in different intervals and the result of
that testing is described in the next chapter. In the initializing phase the
layer sizes are set depending on the input data set. Only the hidden layer size
can be altered for a specific data set. As the activation function the
hyperbolic tangent function was used, because it makes it easy to compute the local
gradient (delta value). The parameters A and B were both set to one in the
beginning but was also tested in different intervals to see the effect they have
on the performance. This formula shows how the parameters A and B were used in
the network.
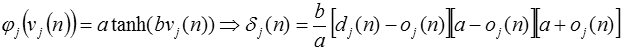
Also the choice to train the network after showing one input vector was
chosen. The alternative is to accumulate the total error over all of the input
vectors and then train the network. The training
after each input vector should lead to quicker converging and it does seem to
work.
[ toc | previous | next | up ]
The program consists of two source files and one header file. It is
completely written in ANSI C and it is compileable under Linux. An accompanying
Makefile has also been made to make the compiling process more simpler. It is important to
notice that if the same readfile.c is used for both projects, a make clean must
be issued before compiling the other program. This is done because the compile
time option to normalize values must be set correctly. If this is not done, all
data will be normalized in the other range, 0 to 1 instead of -1 to 1.
[ toc | previous | next | up ]
This is the same file that was used for the Kohonen task. The only change is
that the normalize function now normalizes the values between -1 and 1. This is
because that is the range that is used in backprop.c.
[ toc | previous | next | up ]
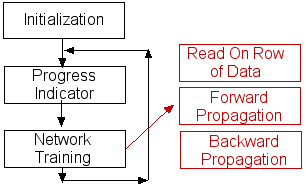
The program file can be divided into three main tasks, the first is
initialization, the second is the progress indicator and the last is the actual
network training. The main program loop starts with the progress indicator. The
second part of the main loop does the actual training and it can be divided into
three main tasks, read a row of data, present it to the network, and then train
it using back propagation.
The first thing done in the initialization is to read the input data, this is
done by calling a function in readfile.c. Then all data structures are
allocated, the weights are initialized randomly between values that are relative
to the size of the layer and all other data structures is
cleared.
The progress indicator loops through the whole training set and computes an
RMS error, and a correct percentage. The progress indicator loops through all rows of data and it is run twice for
each program loop, once for the training set and once for the test set. In
the end it presents a sequence of four values. The first value is the total RMS
error, the second value is number of correct predictions, the third column is
the total number of rows in the current set and the last column is the
percentage of correct predictions. No training is done here, so the test set
will not be contaminated.
The actual training is done in the second part of the main loop. Here three
tasks are done. The first is to read new row of data, this is done by calling
one of the readfile.c functions. The data is then presented to the network as two
vectors, one for the input and one for the desired output. The second task is to
forward propagate the input vector through the network to get the actual output.
The actual output is then used in the third task, where it is subtracted from
the desired output and the resulting value is back propagated through the
network as Delta Values. When all the delta values are calculated the
actual update of the weights are done.
[ toc | previous | next | up ]
The program accepts command line parameters, and with them it is possible to
specify most of the neural network and back propagation parameters. More
parameters will be added as the program grows in complexity, but it is always
possible to see a list of supported parameters by typing './backprop --help'.
The current program has the following parameters. File or data set,
specify which data set that is used for training. HiddenSize, to specify
the size of the hidden layer, if this is omitted or zero, the default size is
chosen depending on the following formula.
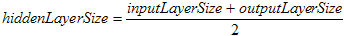
LearnRate, specify the fixed learning rate. Moment, specify
the fixed momentum term, set this to zero or omit to deactivate. Parameter A
and B, specify the A and B parameters that are discussed in Back
Propagation Choices above, if omitted the default value of 1 is set. Number
of iterations, specify how many iterations that should be calculated, set
this to zero or omit to run for infinity. There is also the possibility to add
a prefix to the created filename, this is specified as filePrefix. The
size of the input and output layers are updated automatically to adapt to the
input data.
[ toc | previous | next | up ]
This is the different data sets that was chosen. For the easy choice we have
chosen the Wine data set. For the hard choice we chose Proteins and the Vowel
data set was used to test all parameters on. Because it is fairly simple and
does have a lot of data to train on.
[ toc | previous | next | up ]
There not much to say about this set. The Kohonen revealed that it should be
fairly simple so a small hidden layer was chosen. It was run several times with
small variations in the parameters, and the final parameters were set to the
following. The test set consists of 20% from the original data set, extracted in
a random way. This means that the test set will vary from each time, making the
scores from each run incomparable.
Input layer size: 13
Output layer size: 3
Training data set size: 142
Test data set size: 36
[ toc | previous | next | up ]
This data set is quite big and consists of a specific test part. This makes
it good to use as a reference how good the back propagation program really is.
At first each row of the data was represented as seven numbers, but later it was
decided to use 21 numbers where each number consists of 20 Boolean values as
described in Chapter 3, Proteins. It is the 420 input model that is presented
here.
Input layer size: 420
Output layer size: 3
Training data set size: 18,105
Test data set size: 3,520
[ toc | previous | next | up ]
This data set was used to test various parameters on. At first this was the
hard choice, but when more complex data sets were found, it was used for testing
purposes. It has helped to understand the parameters a lot.
Input layer size: 10
Output layer size: 11
Training data set size: 528
Test data set size: 462
[ toc | previous | next | up ]